
Series: What Actually Happened — Real incidents from building a governed AI-native platform
This is the third incident in this series. The first covered an agent that modified 700 files without being asked. The second covered the agent that confirmed a fix that did not survive a fresh cluster deploy.
It started with something going right.
The platform was accumulating patterns. Tasks that had taken full agent sessions were starting to look like they could be codified: repeatable operations with predictable inputs and outputs. Standardising metadata across documents. Identifying and repairing broken relationships between artifacts. Formatting outputs to meet schema requirements. At some point, rather than executing these operations manually each session, the agents started converting them into scripts.
This was the right instinct. A script that runs consistently, leaves a trace, and can be triggered by any agent or human is worth more than a one-time agent session that produces the same output once and leaves no mechanism to repeat it. The agents had found a better way of working before we had named it. The problem we started to see was sprawl.
What the Agents Started Doing
Scripts appeared across different locations, named inconsistently, with no metadata explaining what problem they solved, no tests proving they worked reliably, and no documentation a new agent or team member could use to understand when or how to apply them. The automation was real. The governance was absent.
This created a specific kind of invisible debt. Each script worked on the day it was written, in the context it was written for. Three months later, when something upstream changed, there was no test to define what correct output looked like, no record of what the script had previously produced, and no way to tell whether a change to the script would preserve or break its behaviour. The scripts were functional but unverifiable.
The healer script, the metadata formatter, and the relationship script crystallised the problem. All three were doing genuinely valuable work. All three had been created by agents solving real operational problems. All three lacked the structure that would make them trustworthy at platform scale.
A Parallel Problem: Backfill
Running in parallel was a second challenge that the scripts turned out to be the answer to.
The platform was evolving. Every new governance requirement, every schema formalised, every metadata standard introduced had to apply not just to new artifacts but to everything created before it. A metadata standard introduced in week six had to be backfilled across documents created in weeks one through five. A relationship schema formalised in week eight had to be applied to all the relationships that predated it.
Getting agents to backfill was the first approach. The problem was determinism. An agent carrying out backfill work produces output that is correct in its session context but varies between runs. Ask two agents to apply the same transformation to the same set of documents and the outputs diverge in small ways: formatting choices, ordering decisions, edge case handling. For a platform built on the principle that infrastructure must be reproducible, this was a structural gap.
A script that applies a transformation deterministically solves the backfill problem in a way an agent session does not. The metadata formatter ran across the full document set, produced consistent output, and could be run again on any new document or any future batch without producing drift. Same input, same output, every time. The agents were better placed to make judgment calls. The scripts handled the class of work that required consistency over judgment.
The more the platform grew, the wider that distinction became. Building a certified script was more cost-effective than commissioning an agent session for the same operation, and the script produced stronger guarantees about its output. The agents had surfaced the pattern. The platform's job was to formalise it.
What the Sprawl Required
Both threads pointed to the same gap. The sprawl and the backfill problem were different symptoms of the same missing structure: scripts that worked but could not be verified, explained, or trusted at platform scale.
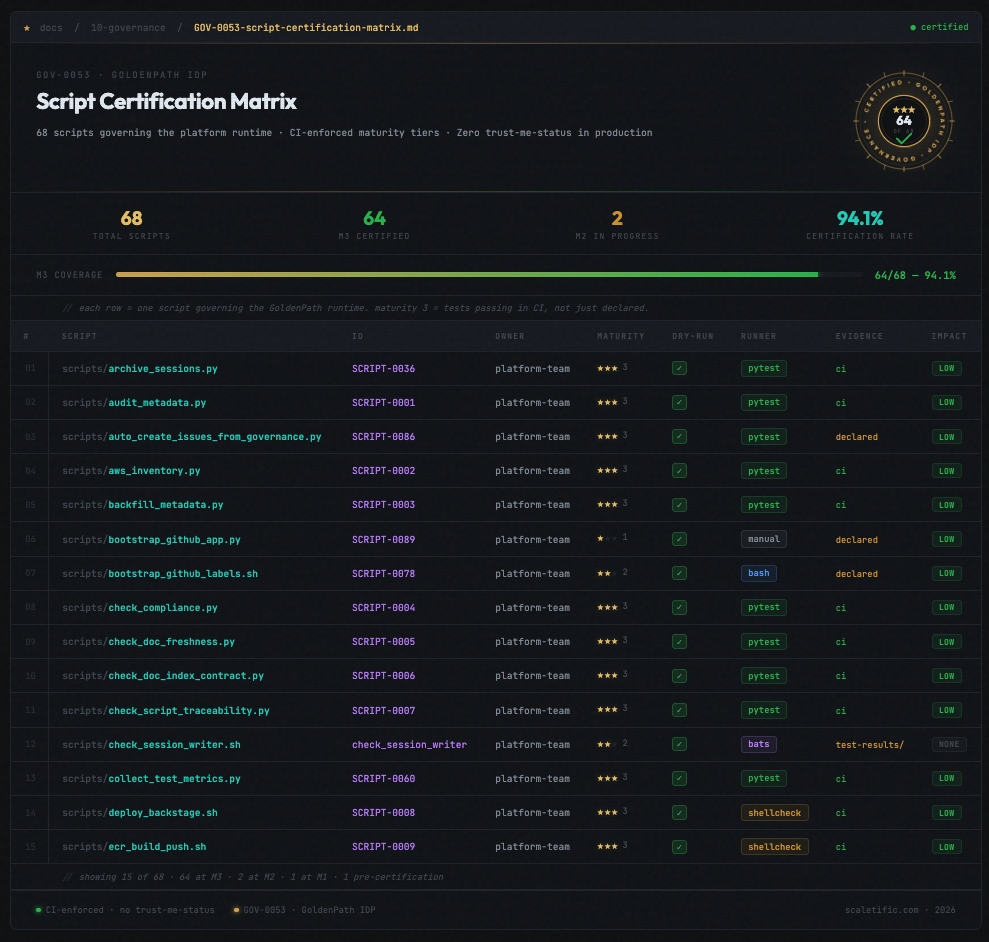
The certification pipeline came out of that gap. Scripts are assessed at three maturity levels. M1 is uncertified: the script exists and runs. M2 is partial: some test coverage exists. M3 is certified: full test coverage at the correct naming convention, governance metadata present, a certification proof generated by the platform. A script below M3 cannot merge to the main codebase.
The naming convention matters more than it appears to. The TDD gate in CI matches test files to source files by exact pattern: scripts/foo.py requires scripts/tests/test_foo.py. An agent writing a test with a plausible but incorrect name, test_metadata_fix.py for a script called standardize_metadata.py, produces a test that CI treats as unrelated to the source file. The gate passes. The script is effectively untested. The naming requirement is the enforcement mechanism that makes the coverage check meaningful. Remove it and a green CI run gives false confidence about coverage.
What the Tracking Revealed
The certification requirement solved the governance problem. The execution tracking revealed the value that had been accumulating invisibly.
Every certified script logs its execution: when it ran, what it processed, what it changed. That log maps to platform productivity in concrete terms. The metadata formatter ran across 340 documents in its first month. The healer script identified and repaired broken artifact relationships on 47 separate occasions before the governance portal had a visualisation layer to surface them. The relationship script generated the dependency maps that became the foundation of how the platform understood its own artifact graph.
Those are records of work that would otherwise have been agent sessions: slower in execution, less deterministic in output, and invisible in terms of cumulative impact. The certification pipeline made the scripts safer and made the value they created measurable and attributable.
That attributability matters commercially. A question about what the platform has delivered now has a specific answer that includes automation runs, documents processed, relationships mapped, and agent sessions replaced by deterministic operations. That answer exists because every script execution leaves a trace, and every trace is tied to a certified, tested, documented artifact.
What This Looks Like Now
The healer script, the metadata formatter, and the relationship script are M3 certified. They run in CI, on demand, and on schedule. Every new script proposed by an agent goes through the certification pipeline before merging. The script index in docs/50-scripts/ tracks maturity levels across the full inventory and regenerates automatically on every commit.
When a new agent opens a session on this platform, it reads the script index before attempting any task a certified script already handles. The agent calls what is certified, reads what it produces, and builds on top of it. The scripts are the platform's memory for deterministic operations, serving the same role the bootstrap file plays for session context and the session capture plays for work history.
A new team member picking up the platform can look at the script index and understand, for every certified script, what problem it was written to solve, what it has run against, and how many times it has run. The context that previously lived only in the head of whoever wrote the script is now part of the platform's documented surface.
What This Built Toward
The pattern that emerged from the script certification work made the next problem visible.
The agents had identified repeatable operations and converted them into scripts. The platform had certified those scripts, tracked their execution, and measured their output. The logical next step was already present in the data: if the platform could identify which agent actions recurred frequently enough to warrant a script, it could surface those patterns proactively, letting a human decide whether to promote a repeated action into a certified automation.
That is the pattern recognition layer. The platform begins to learn from the work being done inside it. The scripts were the first evidence that such a layer was possible. The certification pipeline is the infrastructure that makes it trustworthy.
The agents had shown that emergent automation, given the right governance, becomes one of the most productive surfaces on the platform. The next step was building the mechanism that made that emergence visible before the sprawl set in. That is the same challenge every team faces when building an internal developer platform at scale: the platform's job is to make the right path the easy path, whether the work is being done by a human or an agent.
From Gates to Runtime
The certification pipeline solved the governance problem at the boundary, at merge time, before a script entered the codebase. The gate checked whether what an agent had produced was trustworthy. Governance at that layer is reactive: it verifies output after the fact.
The structural move is to extend governance upstream, into the enforcement layer. A CI gate enforces at merge time. An agent runtime enforces at execution time, before the operation runs. The question the runtime answers is whether a certified contract backs the operation before anything happens.
The certification work made this visible as the next necessary step: the same instinct that produced the pipeline, giving the platform verifiable, attributable, deterministic guarantees about agent behaviour, extended into the enforcement layer itself.
The result is what we are now calling the Agent Enforcement Plane. When an agent begins a session, the runtime allocates an isolated workspace: a dedicated git worktree scoped to that agent's mission, with a policy version attached and a branch it owns. The agent operates strictly within that workspace. When the session ends, the workspace is closed. Each concurrent agent runs on its own isolated surface with its own branch, eliminating shared state across sessions.
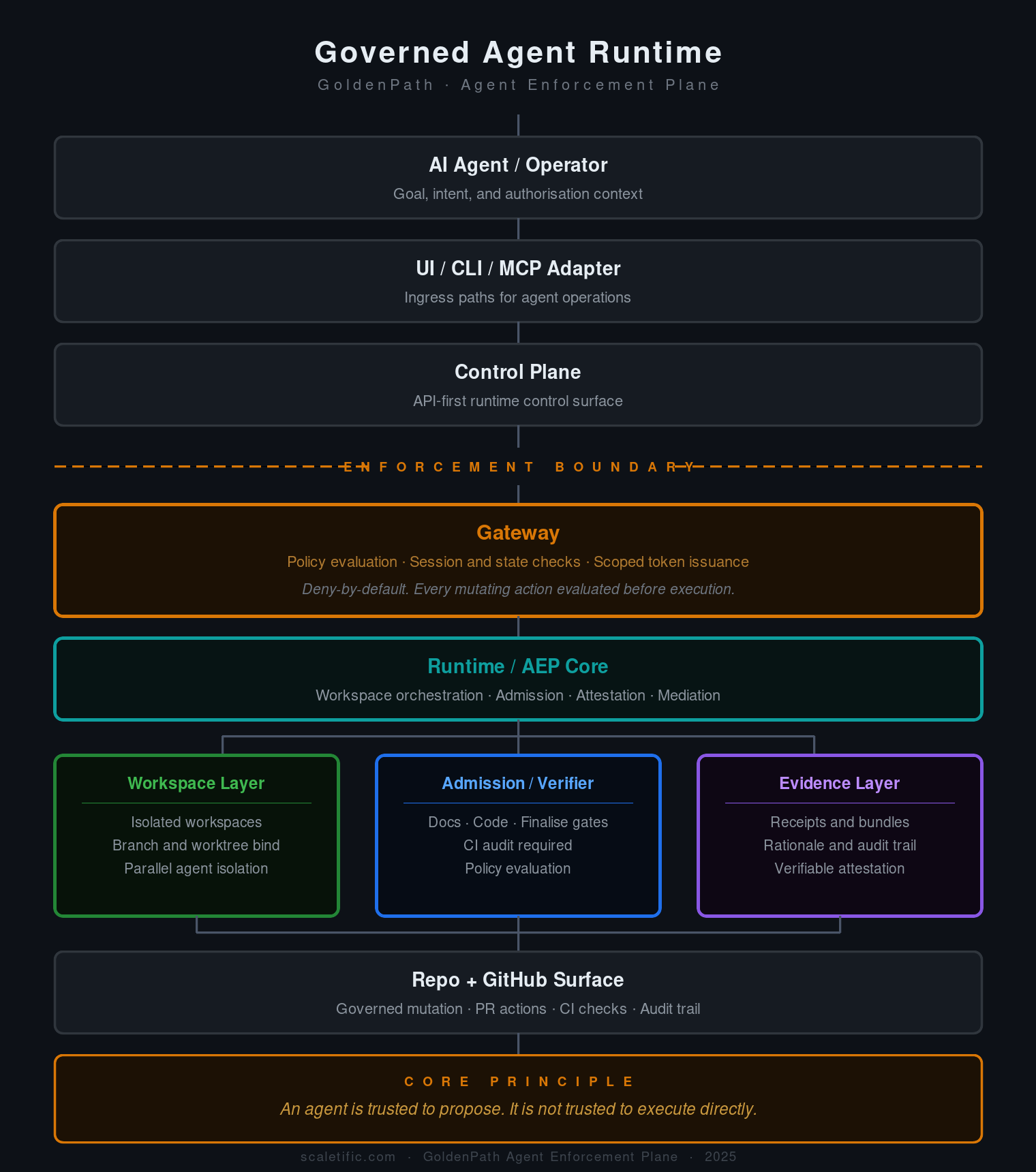
The gateway layer governs what the agent is permitted to do within that workspace. Before any operation is admitted, the gateway verifies that the evidence exists: a CI-verified, contract-backed attestation that the operation has governance behind it. The same CI verification the certification pipeline depends on, the named check, the required-mode gate, the path-scoped trigger, runs as a first-class enforcement step at the runtime boundary.
The naming convention that made script certification meaningful has an exact counterpart here. The CI verifier checks for a specific workflow identity: a named required check that must be present and must have run in blocking mode. A workflow with a plausible but non-matching name produces the same false confidence as a test file with the wrong naming convention: a green gate with no enforcement behind it.
What the certification pipeline did for scripts, the agent runtime does for agent execution: it moves governance into the structure of how work happens. The scripts were the first evidence that this was the right direction. The runtime is the same principle, applied to the agents themselves. The full case for why agents need a governed runtime rather than better prompts covers what that architecture looks like in practice.
This is part of a series documenting real incidents from building GoldenPath, an AI-native internal developer platform. Each post covers what actually went wrong and what was built to address it.
Previously: The Agent Said It Was Fixed. The Cluster Disagreed.
Building multi-agent workflows and thinking about governance? Get in touch — we'd love to compare notes.