
The Problem Nobody Talks About
Every platform team I know is dealing with the same quiet crisis: the documentation is winning.
Not in the good way. In the "we have 690 pages of governance documentation across 193 architecture decision records, 30 policies, 44 runbooks, and 89 certified scripts, and nobody can find anything" way.
We built the GoldenPath Internal Developer Platform to bring order to cloud infrastructure. Terraform modules, GitOps deployments, self-service provisioning, the whole stack. And we governed it properly, every decision documented in an ADR, every policy versioned, every script certified. The governance system worked exactly as designed.
The problem was that the governance system became too successful. We had so much documented institutional knowledge that the documentation itself became a bottleneck. Engineers were spending 10-30 minutes per governance lookup, manually cross-referencing ADRs, tracing policy dependencies, trying to answer questions like "what depends on this TDD policy?" or "which modules need updating if we change the secrets strategy?"
The documentation was comprehensive. The documentation was correct. The documentation was also functionally inaccessible at scale.
This article is about the journey we're on to fix that. Not a finished product, we haven't deployed any of this to production yet. What we have is a working local development stack, a set of architectural decisions we're confident in, and a roadmap we're following one measured step at a time. We're writing about it now because the lessons from getting here are useful regardless of where the journey ends up.
The Obvious Answer (and Why It's Wrong)
The obvious answer is "just build a RAG chatbot." Embed the docs, throw them in a vector database, wire up an LLM, done. Every hackathon in 2025 produced one.
We started there. And then we thought about what actually happens when you ask a basic RAG system "What depends on GOV-0017?"
A vanilla vector search finds documents that mention GOV-0017. It returns chunks that are semantically similar to the query. The LLM stitches them together into a plausible-sounding answer. And that answer might be correct, if the relationships are explicitly stated in the text near each other.
But governance documentation doesn't work that way. GOV-0017 (our TDD and Determinism policy) doesn't just exist in one document. It's referenced by ADR-0180, implemented by PRD-0008, enforced in CI workflows, depended on by 12 other policies, and has been superseded once. Those relationships span dozens of documents, and the connections between them are structural, not textual.
Vector similarity gets you "documents that mention GOV-0017." It doesn't get you "the dependency graph of everything that breaks if GOV-0017 changes."
That's a graph problem. And realising that changed everything about how we approached this.
The Foundation We Didn't Know We Were Building
Here's the part of the story that only makes sense in hindsight.
Long before we wrote a single line of RAG code, we had been building the metadata infrastructure that would make a knowledge graph possible. Not because we planned to build a knowledge graph, but because we needed governance to scale.
Every document in the platform carries structured YAML frontmatter. Not optional, not "nice to have", CI blocks your PR if the metadata is missing or malformed. A typical ADR header looks like this:
---
id: ADR-0180-argocd-orchestrator-contract
type: adr
status: active
domain: platform-core
owner: platform-team
relates_to:
- ADR-0001-platform-argocd-as-gitops-operator
- GOV-0017-tdd-and-determinism
- PRD-0008-governance-rag-pipeline
supersedes: []
superseded_by: []
reliability:
rollback_strategy: git-revert
observability_tier: silver
maturity: 2
schema_version: 1
---
That relates_to field is the key. Every document explicitly declares its relationships to other documents. Not as prose buried in a paragraph, as structured data that machines can traverse. When ADR-0180 says it relates to GOV-0017, that's a typed edge in a graph waiting to be built.
We enforced this across 690+ documents. The metadata standardizer, a script we call "The Healer", runs across the entire corpus and auto-fixes metadata against canonical schemas. If you add a new document without proper frontmatter, the standardizer fills in defaults from the schema skeleton. If you use an enum value that doesn't exist in enums.yaml, CI catches it. If you forget relates_to, the document becomes an orphan node, and orphan detection flags it.
The enum standardization was particularly important. Every domain, every owner, every risk_profile, every lifecycle value comes from a single source of truth: enums.yaml. When a retrieval result says domain: platform-core, that means the same thing in every document across the entire corpus. No drift. No synonyms. No "platform-core" in one place and "core-platform" in another.
Metadata inheritance reduced the boilerplate by roughly 85%. Instead of repeating owner: platform-team in every document under docs/adrs/, a parent metadata.yaml at the directory level provides the default, and children inherit it. Identity fields (id, title) never inherit, they must be local. Everything else cascades down the directory tree, with local values overriding parents.
The result: when we eventually pointed a graph database at the corpus, the edges were already there. Every relates_to became a graph edge. Every supersedes / superseded_by became a temporal relationship. Every domain and owner became a node property. The knowledge graph wasn't built from scratch, it was extracted from metadata that had been accumulating for months.
This is the part of the story that matters for other teams considering this path: if your documentation doesn't have structured metadata, your knowledge graph will be built on inferred relationships (unreliable) rather than declared relationships (authoritative). The metadata infrastructure is the prerequisite, not an afterthought. We just happened to build it for governance reasons before we needed it for AI reasons.
From Simple Graph to Knowledge Graph to Temporal Knowledge Graph
With structured metadata on every document, the evolution toward a knowledge graph had a running start. It still happened in three distinct steps, and each one fundamentally changed what the system could do.
Step 1: Simple Graph, Documents as Nodes, Metadata as Edges
The first step was almost mechanical. Neo4j as the graph database, relates_to fields as edges, document IDs as nodes. The metadata we'd been enforcing in CI became the graph structure.
[GOV-0017] --relates_to--> [ADR-0180]
[PRD-0008] --implements--> [GOV-0017]
[ADR-0182] --extends--> [GOV-0017]
[ADR-0180] --superseded_by--> [ADR-0194]
This was immediately useful, and it was trustworthy because the edges came from validated metadata, not inferred relationships. A graph traversal could answer "what depends on GOV-0017?" by following typed edges that had been CI-validated on every PR. The governance system that enforced metadata consistency was now the quality gate for graph integrity.
But the graph was still document-centric. Edges connected documents to documents. Implicit relationships, documents that discussed the same concepts without explicitly referencing each other, remained invisible. The metadata gave us the skeleton. We needed something to add the flesh.
Step 2: Knowledge Graph, Automatic Entity Extraction
The jump to a knowledge graph changed the unit of analysis from documents to entities. Instead of "Document A references Document B," the system now understood "GOV-0017 defines a testing policy that applies to Terraform modules, API services, and bootstrap scripts."
This is where Graphiti on Neo4j became critical. Graphiti doesn't just store nodes and edges, it automatically extracts entities from text, detects relationships between them, and deduplicates across sources. Feed it a session transcript or a new ADR, and it identifies that "TDD policy," "GOV-0017," and "the testing governance mandate" are all referring to the same entity.
The queries that became possible were qualitatively different:
- "Which Terraform modules are affected by this policy change?" (entity traversal, not text search)
- "Are there contradictions between ADR-0164 and GOV-0021?" (cross-document relationship analysis)
- "Show me all policies that apply to the bootstrap sequence" (concept-level query, not keyword match)
The graph was no longer a companion to vector search. It was becoming the primary knowledge structure, with vectors providing the semantic bridge for queries that didn't map cleanly to entity traversal.
Step 3: Temporal Knowledge Graph, Memory That Knows When
The third step was the one that most RAG implementations never take: adding time.
The problem with a static knowledge graph is that it represents the world as it is right now. But governance documentation changes. Policies get superseded. ADRs get deprecated. Decisions that were true in January are no longer true in March. And critically, agents working on the platform need to know not just what the current state is, but what changed and when.
Graphiti solved this with temporal episode management. Every interaction with the system, every query, every agent session, every document ingestion, becomes an episode with a timestamp. Entities carry temporal metadata: when they were first observed, when their relationships changed, when facts about them were updated.
This enabled something we didn't originally plan for: agent memory across sessions.
Session 1 (Monday):
Agent analyses GOV-0017 dependencies
Graphiti stores: [GOV-0017 depends_on ADR-0180, PRD-0008, timestamp=Monday]
Session 2 (Wednesday):
Agent asks: "What do we know about GOV-0017?"
Graphiti returns: Dependencies found Monday, plus any changes since then
Agent continues where Session 1 left off, no re-analysis needed
Without temporal awareness, every new context window starts from zero. The agent re-reads the same documents, re-discovers the same relationships, re-derives the same conclusions. With Graphiti's temporal graph, knowledge accumulates. An agent working on sub-task 3 of a PRD can recall what agents learned in sub-tasks 1 and 2, not by re-reading their outputs, but by querying the shared knowledge graph for entities and relationships that were recorded during those sessions.
The temporal dimension also introduced a capability we hadn't anticipated: fact evolution tracking. When a policy is superseded, the old relationship doesn't disappear, it's marked with an end timestamp, and the new relationship is recorded with a start timestamp. The system can answer "What was the secrets strategy before ADR-0006 was updated?" because the historical graph state is preserved.
The Hybrid Retrieval Architecture
The three evolution steps produced a retrieval architecture, running locally, not yet deployed, that uses three complementary strategies:
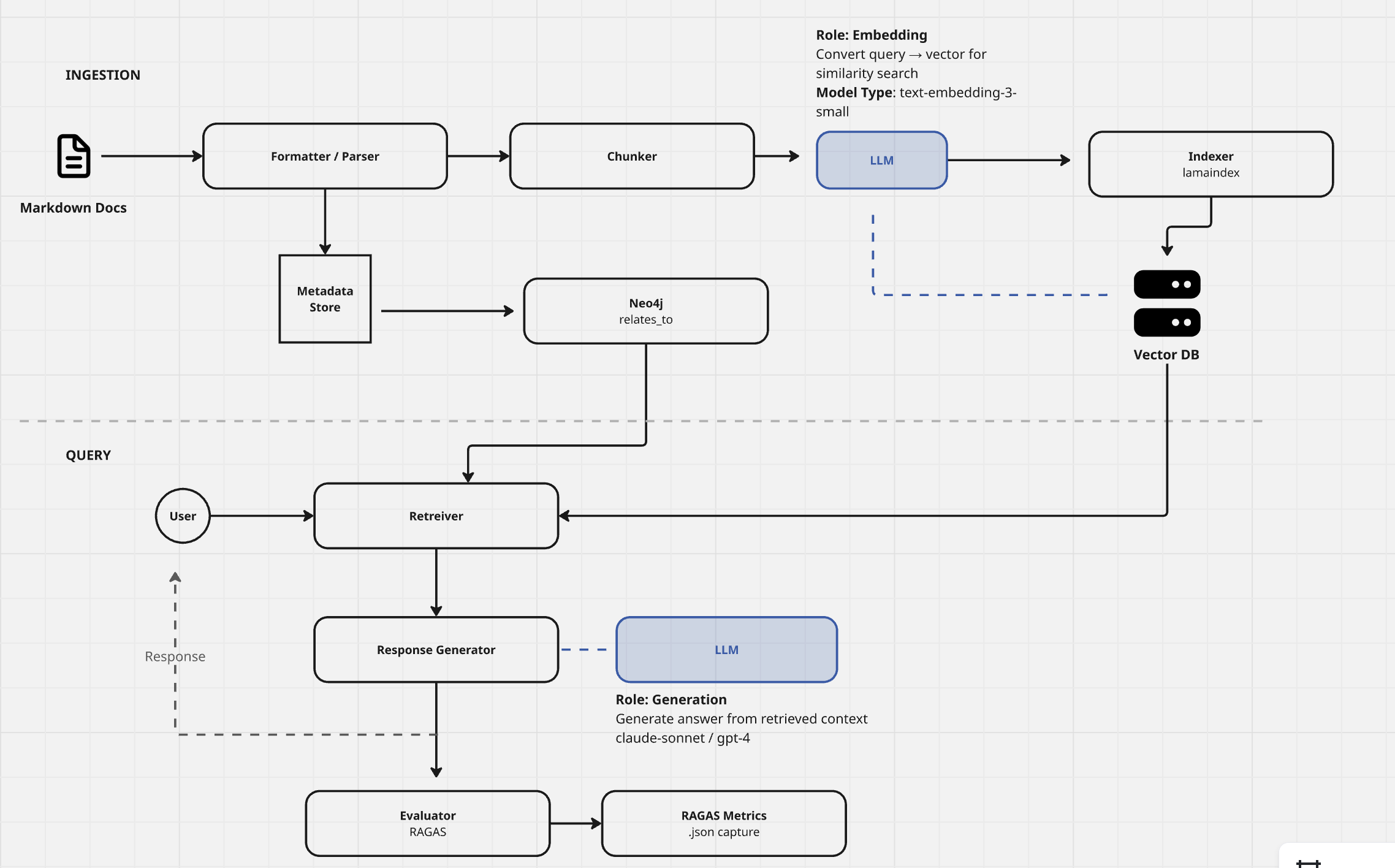
Vector Search (ChromaDB), semantic similarity over 690+ pages of embedded documentation. Answers "what documents are conceptually related to this query?" Best for exploratory questions where the user doesn't know exactly what they're looking for.
Graph Traversal (Neo4j + Graphiti), structured relationship queries over the knowledge graph. Answers "what entities are connected to this entity and how?" Best for dependency analysis, impact assessment, and relationship mapping.
BM25 Keyword Search, sparse retrieval for exact term matching. Catches cases where vector embeddings miss specific terminology (e.g., "GOV-0017" as an exact identifier, not a semantic concept).
The HybridRetriever combines all three, with a result reranker that uses the LLM to score relevance before synthesis. The ranking isn't just "most similar", it's "most useful for answering this specific question given these specific retrieval results."
Contract-Driven Outputs: Treating AI Like Infrastructure
Here's where the IDP mindset changed the approach fundamentally.
In infrastructure, every API has a contract. Terraform modules have input variables and output values. CI pipelines have defined artifacts. Helm charts have values schemas. Nothing runs without a defined interface.
We applied the same principle to AI outputs. Every response from the inference layer conforms to an AnswerContract, a JSON Schema that enforces:
{
"answer": "The structured response text",
"evidence": [
{
"graph_id": "ADR-0180",
"file_path": "docs/adrs/ADR-0180.md",
"source_sha": "a1b2c3d"
}
],
"limitations": "What this answer doesn't cover",
"next_step": "Suggested follow-up action",
"timestamp": "2026-02-12T10:30:00Z"
}
The contract enforces a hard rule: every answer must include evidence (source documents with file paths and commit SHAs) or explicitly declare "answer": "unknown" with empty evidence. There is no middle ground. The system cannot return a confident-sounding answer without citing its sources, and it cannot silently omit gaps in its knowledge, limitations must be surfaced.
This isn't just good practice. It's the same governance applied to AI that we apply to infrastructure. A Terraform module that silently fails is a bug. An AI system that confidently hallucinates is the same bug wearing a different hat. The contract makes the failure mode explicit and detectable.
Schema validation runs on every response before it reaches the user. Responses that fail validation are rejected, not displayed. This is the AI equivalent of a CI gate, if the output doesn't conform to the contract, it doesn't ship.
Three Access Paths Today, More Planned
The retrieval and synthesis layer needs to serve different consumers in different contexts. A developer debugging a Terraform module needs a different interface than a CTO reviewing platform governance. An AI agent orchestrating a multi-step task needs programmatic access, not a chat window.
So far we've built three access paths, all consuming the same underlying primitives:
CLI, rag query "What depends on GOV-0017?" for terminal-native developers. Fastest feedback loop, integrates with existing shell workflows.
API, POST /ask with JSON request/response for service-to-service consumption. Other platform services can query governance knowledge programmatically.
Web UI, React-based chat interface with expandable source evidence, document viewer, and provider selection. The interface that non-technical stakeholders can use without touching a terminal.
Next on the roadmap is an MCP Server, a Model Context Protocol integration that would let AI agents like Claude query the governance knowledge base as a tool within their own reasoning loops. The specification is written (PRD-0010), but the implementation hasn't started yet. When it lands, it'll be how we eat our own dogfood, agents using the RAG system to inform their own work on the platform.
All three current paths hit the same FastAPI backend, which delegates to the same HybridRetriever and RAGSynthesizer. The retrieval logic, contract validation, and observability are shared, no path gets a different quality of answer. The MCP server will plug into the same backend when it's built.
Observability: Every Inference Call Is Traced
In the local dev stack, we run Phoenix (Arize) with OpenTelemetry for full distributed tracing on every inference call. Three span types classify every operation:
- RETRIEVER, vector search, graph traversal, BM25 ranking
- CHAIN, LLM synthesis, question processing
- GUARDRAIL, contract validation, output quality checks
Every query generates a trace that shows exactly what was retrieved, how it was ranked, what the LLM received as context, and whether the output passed validation. When an answer is wrong, the trace tells you whether the problem was retrieval (wrong documents surfaced), synthesis (bad prompt or model behaviour), or validation (contract too loose).
This wasn't a nice-to-have. It was a lesson learned the hard way: without per-request tracing, debugging AI systems is guesswork. "The AI gave a bad answer" is not actionable. "The retriever returned 3 irrelevant chunks because BM25 weighted an exact keyword match over semantic relevance, and the synthesizer couldn't produce a coherent answer from the context" is actionable. Even on a local workbench, this kind of visibility changes how you iterate.
We also learned a specific Phoenix lesson: the default use_temp_dir=True parameter means your trace data lives in /tmp and vanishes on restart. If you want persistent observability, even locally, you need to explicitly set use_temp_dir=False and configure PHOENIX_WORKING_DIR. The default is ephemeral. Observability you lose on restart isn't observability.
The Maturity Model: A Roadmap, Not a Trophy Case
We didn't try to build the end state all at once. Early on, we wrote a maturity model (GOV-0020) that defines five levels, each gated by measurable outcomes, not feature checklists, not sprint deadlines, but actual quality metrics. It's a roadmap for earning trust incrementally.
Here's where we are today, and where the road goes from here.
Level 0, Foundational RAG (where we started): Basic vector search, CLI interface, Phoenix tracing. Exit gate: RAGAS baseline established with 20+ test questions. This is where you prove retrieval quality is real, not imagined.
Level 1, Hybrid RAG (where we are now): Knowledge graph added, multi-hop queries, BM25 hybrid retrieval, Web UI. Exit gate: RAGAS context precision of 0.75 or higher. This is where you prove the graph adds measurable value over vectors alone. We're running this locally and iterating on retrieval quality, it works, but it hasn't been hardened for production or tested beyond our own corpus.
Level 2, Corrective RAG (next on the roadmap): Self-evaluating retrieval with confidence scoring, automatic re-retrieval on low confidence. Exit gate: false confidence rate below 5%, precision above 0.85. This is where the system learns to know when it doesn't know. We haven't started this yet.
Level 3, Agentic RAG (future): Multi-tool orchestration with ReAct reasoning. Six or more tools available (vector search, graph query, catalog lookup, file read, module listing, test checking). Exit gate: 85% task completion rate, 90% tool selection accuracy. This is where the system would become an agent, not just a query engine.
Level 4, Autonomous IDP (aspirational): Agents propose and execute platform changes with human approval workflows. Change proposals, compliance auditing, remediation suggestions. Exit gate: 70% proposal acceptance rate, less than 10% false positive rate on compliance violations.
The principle behind this model is simple: trust is earned through measured capability. You don't skip to Level 3 because you're excited about agents, you get to Level 3 when Level 2's quality metrics prove the system is ready. We might never reach Level 4. That's fine. The model exists to prevent us from running ahead of our own evidence.
At each level, the governance controls tighten rather than loosen. Level 0 is read-only. Level 3 would have tool allowlists, iteration limits, and full invocation logging. Level 4 would require human approval for every write operation, with auto-reject after 48 hours and an emergency stop mechanism. More capability means more governance, not less.
The Vision: Composable Inference as a Platform Primitive
Here's where the story shifts from what we've built so far to where we think this is going.
Everything described above, vector store, knowledge graph, temporal memory, LLM gateway, contract validation, observability, was built to solve one problem: governance documentation retrieval. But these components are independently useful. They just happen to be wired together in one pattern right now.
The Governance RAG pipeline is a composition pattern. It's not the only one possible.
A simple vector RAG skips the graph entirely, embed, retrieve top-k, synthesize. For use cases where relationship context isn't needed. Same observability, same contracts, same provider abstraction.
A graph query engine skips vector retrieval, traverse the knowledge graph and summarise findings. "What depends on ADR-0164?" doesn't need embeddings. It needs graph traversal.
A contradiction detector takes two documents, retrieves related context from both vector and graph sources, and asks the LLM to identify conflicts. Different contract schema (contradiction report, not answer), same underlying primitives.
A memory-aware agent uses Graphiti's temporal knowledge graph without querying the document corpus at all, just recalling what was learned in previous sessions. This is the primitive that makes agents stateful across context windows.
Each of these compositions uses a different subset of the same platform primitives. The infrastructure investment pays dividends across every pattern, not just the one that motivated the build.
The gap we're filling isn't "AI frameworks", LangChain, LlamaIndex, and Haystack already exist. It isn't "managed AI services", Bedrock, Vertex AI, and Azure AI Studio already exist. The gap is governed, composable inference as an Internal Developer Platform capability, where every LLM call is traced, every output is contract-validated, quality is measured in CI, providers are swappable, and the governance layer ensures production-grade outputs.
That governance layer is what transforms a collection of AI tools into a platform.
Where We Actually Are
Let's be direct about what exists today and what doesn't.
A reviewer of our architecture document put it bluntly: "Right now you have a sophisticated personal workbench, not a platform." That's accurate. Everything described in this article runs on a local development machine. Neo4j, ChromaDB, the FastAPI backend, the React frontend, Phoenix tracing, all local. Nothing is deployed to production. Nothing has been tested with real users beyond ourselves.
The composable inference platform claim is currently supported by one working composition pattern. The architecture looks composable, but composability is only proven when a second pattern successfully reuses the same primitives differently. That's a critical proof point still ahead of us.
What we do have is the foundation we trust. RAGAS metrics run in CI like unit tests. Every response is contract-validated. Every query is traced. The governance system that built the IDP is the same governance system that governs the inference layer. That's not a bolted-on afterthought, it's the architecture. And it works locally.
The distance between workbench and production platform is real. Deployment to EKS, multi-tenancy, cost attribution, feedback loops, operational alerting, the MCP server, all of it needs to be built. We're sharing this now not because we've arrived, but because the journey itself, the decisions, the mistakes, the architecture that emerged, is useful to other teams starting down the same path.
What's Next
This is Part 1 of a series. We're writing these articles as we build, not after we've finished, so subsequent parts will reflect what we've actually learned at each stage:
- Part 2: Building the hybrid retrieval engine, ChromaDB vectors, Neo4j graph, BM25 keyword search, and why all three matter
- Part 3: Access paths, CLI, API, and Web UI today; MCP Server next; and how they share one inference layer
- Part 4: Making AI outputs production-grade, TDD on inference, Phoenix observability, contract validation
- Part 5: The road to production, deployment, operational hardening, and what changes when other people use your system
Each article will include the specific technology choices, the tradeoffs we considered, the mistakes we made, and the metrics that told us whether it was working. Some of these decisions will turn out to be wrong. We'll write about those too.
This article describes the emerging architecture of the GoldenPath Internal Developer Platform's inference layer. The system currently runs as a local development stack using ChromaDB, Neo4j, Graphiti, and multi-provider LLM synthesis. It is not yet deployed to production. The platform is governed by 193 ADRs and 30+ policies, and the same governance principles are applied to AI outputs.
Building your own IDP or exploring RAG for governance documentation? Get in touch, we'd love to compare notes.