The CNCF Cloud Native AI Whitepaper
Kubernetes has become the de facto cloud operating system. AI is reshaping every industry. But running AI workloads on Kubernetes? That's where the friction lives.
The CNCF TAG Runtime's Cloud Native AI Working Group published a whitepaper,Cloud Native AI, that maps this friction in detail.
It defines Cloud Native AI (CNAI) as "approaches and patterns for building and deploying AI applications and workloads using the principles of Cloud Native",and it's the most thorough treatment of the subject from the cloud native community.
Two Worlds Colliding
Cloud native was built for stateless microservices, scale horizontally, fail fast, recover automatically. AI/ML workloads are fundamentally different:
-
Stateful by nature, training runs that can't be interrupted, model weights that must persist
-
GPU-hungry, computational demands that dwarf traditional workloads
-
Data-intensive, datasets doubling every 18 months
-
Long-running, training jobs that run for hours or days, not milliseconds
The whitepaper doesn't pretend these are trivial differences. It maps them across the entire ML lifecycle.
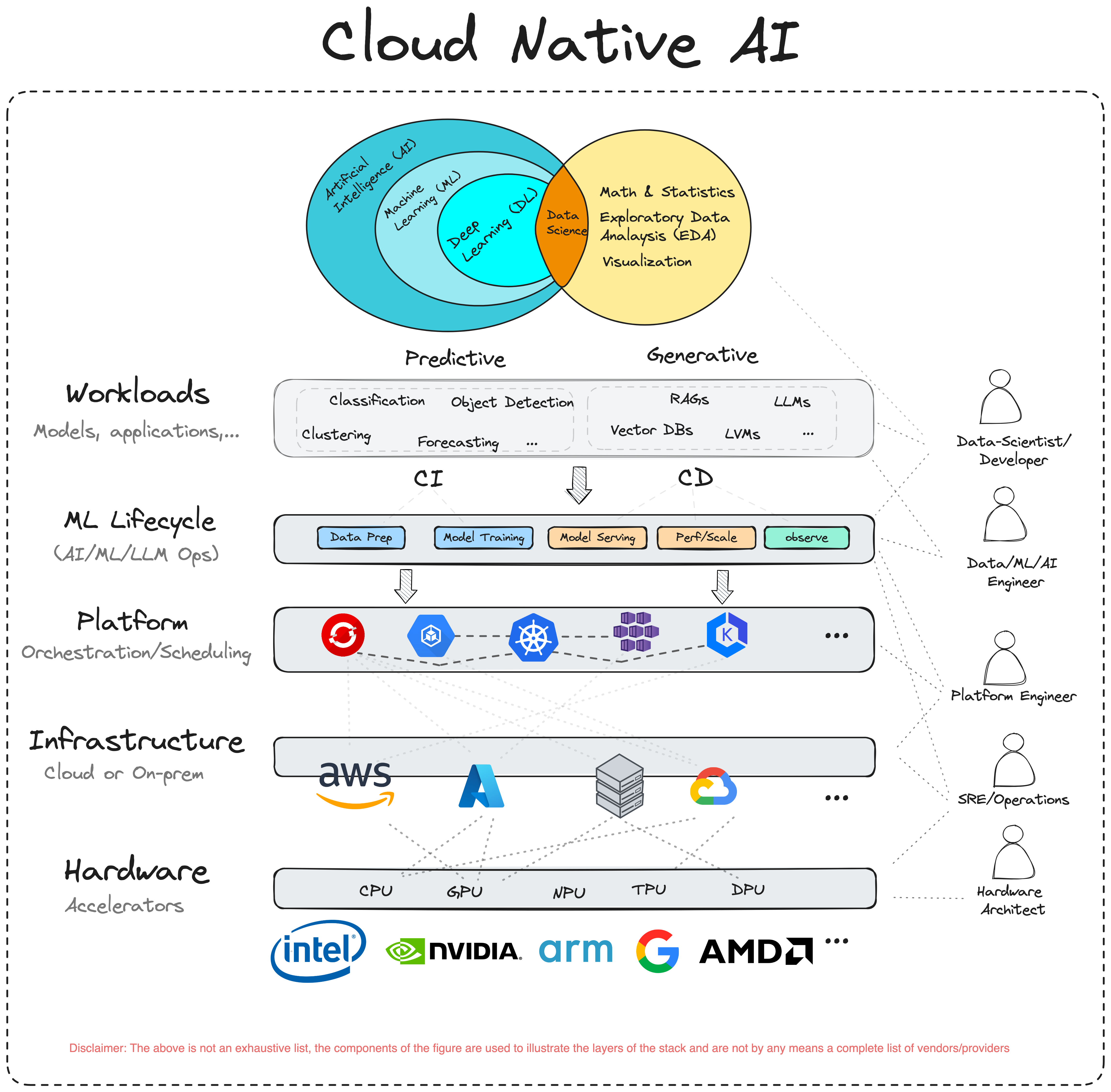
Challenges Across the ML Lifecycle
The paper organises challenges into five phases, each with distinct infrastructure requirements.
Data Preparation
Data volumes are massive and growing. Synchronising local development with production environments is painful. And data governance, privacy, bias, ownership, adds non-trivial constraints that most cloud native tooling wasn't designed to handle.
Model Training
Rising computational demands require GPUs, TPUs, and specialised accelerators. GPU virtualisation (vGPU, MIG, MPS, DRA) is still immature. Distributed training requires sophisticated orchestration, and reproducibility is hard when dependencies are complex and environments differ.
Model Serving
Serving classical ML versus LLMs requires fundamentally different architectures. Model placement and resource allocation decisions are complex. Event-driven patterns need different infrastructure than request-response.
User Experience
Steep learning curves for non-ML-specialists. Fragmented tooling where data tools don't integrate cleanly with ML tools. Debugging distributed training jobs remains a nightmare.
Cross-Cutting Concerns
Observability needs to extend to model drift, not just infrastructure health. Cost control across expensive GPU workloads is essential. Security and compliance must cover model artefacts. And sustainability tracking for carbon-intensive training runs is becoming a regulatory requirement.

Generative AI vs. Predictive AI
The whitepaper draws a clear distinction between the two dominant AI paradigms:
| Aspect | Generative AI | Predictive AI | |--------|---------------|---------------| | Compute | Extremely high, specialised hardware | Moderate, general-purpose capable | | Data | Massive, diverse datasets | Specific historical data | | Scalability | Highly elastic | Moderate elasticity | | Storage | High-performance, diverse types | Efficient, structured focus | | Networking | High bandwidth, low latency | Consistent, reliable |
This distinction matters for platform builders. You can't serve both paradigms with the same infrastructure patterns.
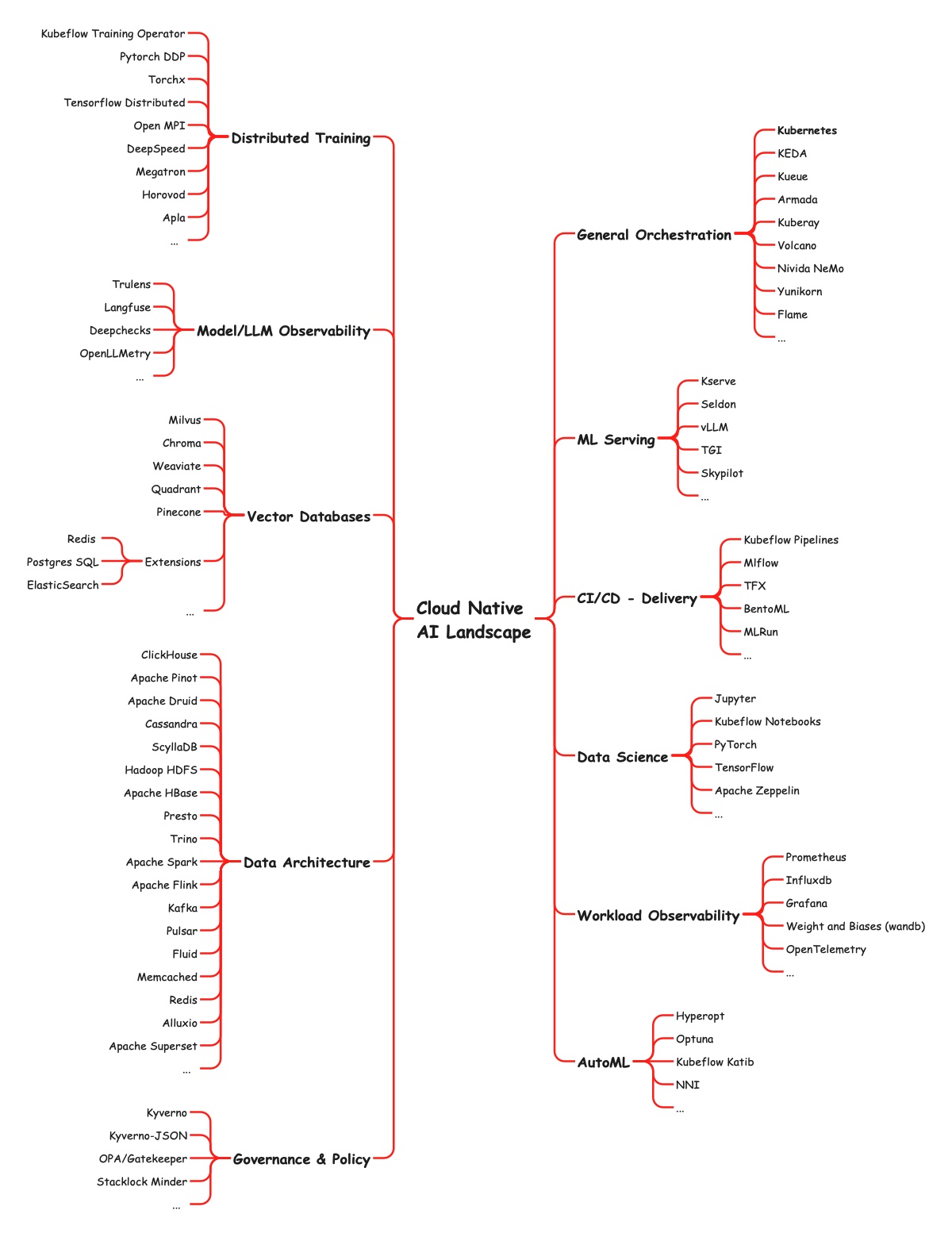
The Cloud Native AI Toolchain
The whitepaper maps the emerging CNAI ecosystem across several categories:
-
Scheduling and orchestration, Yunikorn, Volcano, Kueue for batch scheduling. Gang scheduling for distributed training. Dynamic Resource Allocation (DRA) for flexible GPU management.
-
ML platforms, Kubeflow for end-to-end ML operations: Training Operator, Katib for hyperparameter tuning, KServe for model serving.
-
Data and features, TorchArrow, PyIceberg for large-scale data loading. RayData and Arrow Flight RPC for I/O optimisation.
-
Serving, KServe for autoscaling inference. KEDA for event-driven workloads. OCI format for model portability.
-
Observability, OpenTelemetry as the foundation. OpenLLMetry for LLM-specific tracing. Model drift detection tools.
-
Security, Grype and Trivy for scanning. Kyverno for policy enforcement. Trusted Execution Environments for sensitive workloads.
AI Enhancing Cloud Native
The paper also explores the reciprocal relationship, how AI improves cloud native operations:
-
Natural language interfaces for cluster control, demonstrated at Cloud Native AI + HPC Day 2023
-
ML-driven security, anomaly detection and threat identification
-
Intelligent orchestration, pattern analysis for workload optimisation and resource scheduling
-
Log analysis, custom LLMs trained on operational data
This bidirectional relationship is important. AI isn't just a workload that runs on Kubernetes, it can make Kubernetes itself smarter.
What This Means for Platform Engineering
If you're building an Internal Developer Platform, AI workloads are coming, if they haven't arrived already. The whitepaper highlights several implications:
-
GPU management is a platform concern, scheduling, sharing, and cost allocation for GPU resources needs to be a first-class platform capability
-
ML pipelines need golden paths, data scientists shouldn't need to understand Kubernetes networking to train a model
-
Observability must extend to models, monitoring CPU and memory isn't enough when model drift is the real failure mode
-
Security models must cover model artefacts, model supply chain security is the next frontier
At Scaletific, our RAG pipeline architecture already incorporates these principles: vector databases (ChromaDB), graph stores (Neo4j), retrieval-augmented generation with guardrails, and full observability through OpenTelemetry.
The Path Forward
The whitepaper concludes with five recommendations:
- Flexibility, Leverage existing tools while accommodating rapid evolution
- Sustainability, Support environmental impact transparency
- Custom platform dependencies, Ensure GPU driver support and acceleration
- Reference implementations, Create integrated, user-friendly tool combinations
- Standardised terminology, Align on evolving AI/ML language
The organisations that figure out Cloud Native AI infrastructure will have a massive competitive advantage. The gap between "we run AI experiments on laptops" and "we have production AI infrastructure" is exactly where platform engineering lives.
Read the full whitepaper: CNCF Cloud Native AI Whitepaper
Building AI infrastructure on Kubernetes? Let's talk, we build the platform layer that makes it work.